

(This is Part 3 in a 5-part series.)
In Part 1, we discussed how when we focus on lean thinking, we can accomplish more, reliably and consistently. In Part 2, we discussed these ideas:
- Local variation can enhance the work and create a learning organization.
- Consider how you use standups.
- Focus coaching on the environment and the team, not the people.
We illustrated how the intentional local deviation from standard processes enables a learning organization and how a meeting culture focused on that idea enhanced that even more.
Instead of a team as its own island, consider any individual team’s system in the context of the larger system. Then, if we take a systems view of the work, we can enhance outcomes, especially if we gather useful data.
This part discusses how data can support a team’s decisions. Let’s start with Pull
Pull
Pull is another one of those concepts that has more than one meaning, even in agile development. Let’s look at two different ways to look at pull. Pull as a kind of personal freedom and pull as a property of the systems.
In lean the term is mostly used to describe a property of a system as an alternative to scheduling work from the outside. Having a pull system doesn’t say anything about who is doing the pulling – whether it is an external coordinator or the people within the system.
In a system that is governed by the pull principle, the reason for a work item to move into the next stage is a combination of two things: the work on the item in the current stage has to be completed (it has to be ready to pull), and a pull signal in the next stage has to occur.
If you know the capacity of your system and have limited the WIP in the system accordingly, this pull signal occurs each time the WIP-limit of a stage is not exhausted. Thus some people in the Kanban-communities started to refer to WIP-limits as WIP-targets. Without the aim to fill the system to capacity, there is no pull.
Here is an example of where a team can see a signal to pull work.
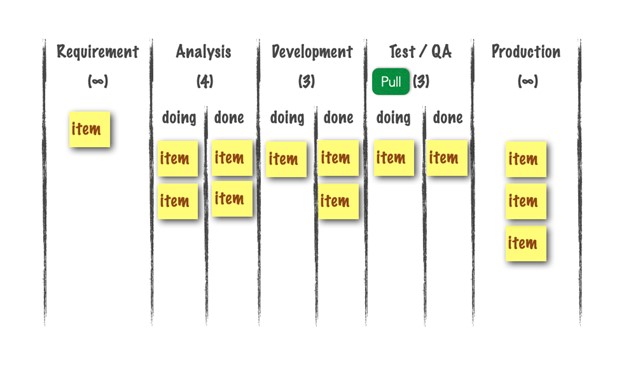
Open pull signal in “Test / QA” (Target:3, current2). The team has capacity in Test/QA, so the team can pull work into Test/QA. Note that in the real world the pull signal is usually not visible! There it is ‘only’ the difference between target and current WIP.
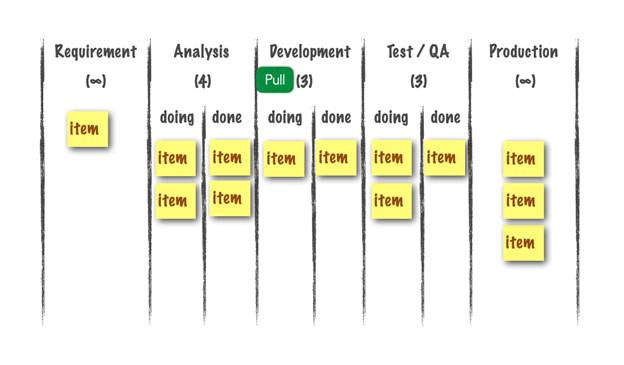
As you can see, satisfying this pull signal generates a new pull signal in “Development” (WIP-target:3 current:2), which in turn generates a new pull signal in “Analysis” when it is fulfilled.
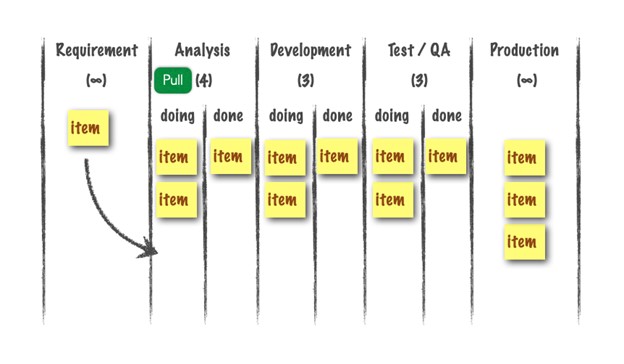
Finally, there is pulling the last requirement into the system. That is what is meant by “pulling work through the system from right to left.”
All of this happens as soon as the situation arises, not at any fixed point in time. In this sense, WIP-driven pull oriented systems are completely signal-driven.
Yet, having a pull system doesn’t say anything about who does the selection of the work. In this manner, we could still have a manager decide which of the items in Development to pull, and still have a pull system.
The other kind of pull –which is often called self-signup in lean environments and self-managing in the agile literature– implies the personal freedom of teams and individuals to choose their work items.
On the upside, this interpretation leads to a higher motivation because of more perceived autonomy. For too long, project managers, managers, even technical leaders told people what to do. On Monday, you checked in with the boss, and he (or she) told you what to do. You probably worked on a task, not an outcome.
You did the same on Tuesday, Wednesday, Thursday, all week. You continued to get work in dribs and drabs from some form of manager who handed out work.
We don’t know of too many people who enjoyed that kind of work assignment.
Now, with a pull approach in a team, people can select the work they want to do. This self-selection at the individual level helps people feel connected to the work (purpose). The people feel autonomy with the self-selection, and they can create new mastery when they choose to learn something new.
We can use pull as a system for the team and for the entire organization. Let’s first start with the team’s perspective.
Especially in teams just emerging on their agile journey, we have often seen that pull is understood only as this second kind of pull without taking pull as a systemic property into account. More often than not, this creates a system where people are free to choose what to work on and still create a system that behaves as a push system. (No limited WIP, Blocked items. etc.)
That means if you want to use pull as an approach, you first recognize the pull system as a team.
The team limits its WIP and uses signals as a team to choose what to work on next. Inside that system, people can choose what to work on next. They might choose to work on something new to them. In that case, because the team limits its WIP, the person who wants something new often works with other people. They create a learning team. (There’s a term for this: symmathesy.)
While we see at least three options on where to start with limiting WIP and optimizing for the respective system (team-level, coordination-level and portfolio-level), we also see the need to keep the evolution of the different levels more or less in sync to really develop the whole organisation in a healthy way.
And as Klaus Leopold used to point out, you have to limit the work on the level on which you want to see results. So, if you want shorter time to market times for your products, that is the level that you have to limit. That level is the portfolio level or the coordination level, not the team level.
Once you realize that teams need to optimize for their WIP, you see that the idea of optimizing up for the WIP at each level of the organization makes sense. In fact, if the organization starts managing WIP at the portfolio level and then only asks teams to work on one project or product at a time, the teams will find it easier to manage their WIP. Then, people will also find it easier to manage their personal WIP.
Even in flow organizations, people sometimes have problems with WIP. The organization has a new opportunity, and “someone” needs to work on it. In that case, the organization has to decide what to postpone for now. When we manage our WIP at every level, we focus on the most important work and we finish it faster. When we don’t manage our WIP, we don’t focus. People become overwhelmed and overloaded.
That was not the purpose of the Agile Manifesto.
Visualize the Actual Data
We use cycle time (and lead time) as the basis for estimation. We do this because story points and velocity are a measure of capacity, not time.
When teams use their capacity, such as the number of story points for several stories, they omit the largest time in their work—that of delays. Instead, we have found that either of these two ways of estimation works:
- Counting what teams can complete in a given time. For example, a team regularly completes two stories, two fixes in one week.
- Cycle time, the time it takes a team to complete a story, from start to finish.
We recommend teams measure their counts or cycle time over several weeks and look for their distribution. Even cycle time or counting can lead to underestimation. That’s because features don’t arrive at the same arrival rate, and the features might not be split to be relatively the same size.
How can we create good conditions for estimation? We’ll address the ideas behind splitting stories, cycle time, and customer lead time.
Splitting Stories, Features or Requirements
Many teams say they use “stories” as a way to define value in the product. Stories are only one way to express customer needs, and our elaboration applies to all the other types as well.
When teams try to estimate or forecast the time they need, we more often see feature sets or some other “requirements” as the unit of work. Teams often feel they don’t have the time they need to:
- Perform the necessary analysis on the feature set
- Split the feature set into the multiple small stories or features
- Discuss alternative architectures or user interfaces—all of which will affect the duration of the work.
That means that if the team needs to create a forecast that has a higher than 50% accuracy, the team needs to spend more time on the analysis part of the work.
In our experience, teams need several analysis discussions. They need the whole-product, whole-feature set, and immediate backlog discussions. Too often, we don’t see teams take this time.
Because teams don’t perform all the analysis up front, they often don’t have the time they need to split feature sets into “all” the stories. When teams can’t see “all” the small stories, their estimates are overoptimistic. That’s where the team’s cycle time can help, even if the team can’t take the time for all the analysis. The team’s cycle time incorporates the team’s delays into the forecasts.
On an organizational level we also need to consider the customer lead time, so we know when the customer can use the team’s finished work. If you work in an organization where your team cannot deploy at will, your team has delays that their local cycle time does not account for. You will also need to use customer lead time for your forecasts.
Cycle Time
While we might think everyone can agree on cycle time and lead time, we find that the context makes a difference.
In this context, we use cycle time as the time it takes for a work item to pass through the team’s value stream from commitment point to delivery.
Here’s a “best example” value stream we have seen at our clients:
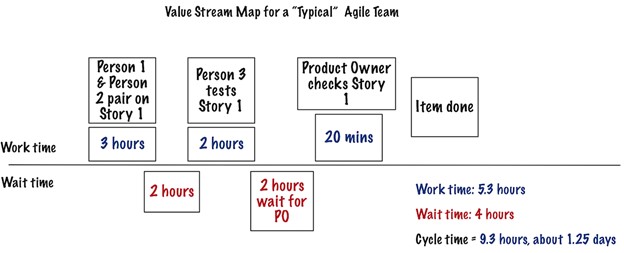
All work time is above the line. All wait time is below the line. In this team, the first two people paired on the story for three hours. Because the tester was not available for two hours, the item waited for the tester to be available.
Once the tester finished his work, the team waited for the product owner. The PO checked the story and accepted the story.
The team worked on this story for 5.3 hours. The team incurred 4 hours of wait states. That gives a total duration of 9.3 hours of cycle time.
While we prefer to see lower wait times in agile teams, we recognize many teams have longer cycle times because the team waits for people in the team or people not in the team.
When we say “best example,” we mean the least wait time. We often see wait times of days or weeks for hours of work, especially when it comes to the complete customer lead time.
Lead Time
In this context, we use lead time as the time it takes for a customer to be able to use a work item.
This same client had this lead time, the additional time the “team” needed to deploy the item:
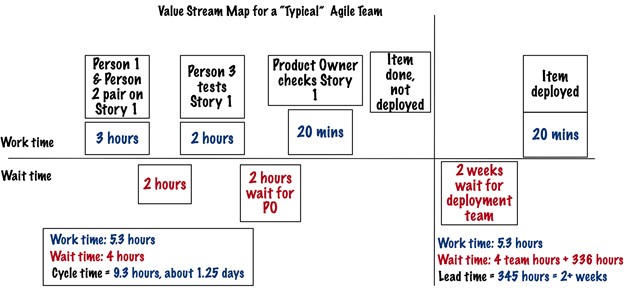
After the team completed the item, the team had to wait for the deployment team to deploy the change. The deployment team batched items.
This team’s cycle time was reasonable compared to the lead time, the first time a customer could see the finished work.
We see too many coaches and other team-based leaders focus on what’s inside the team, instead of the entire system. If a deployment team always takes a minimum of two weeks to deploy a change, the team doesn’t have to change its cycle time. Someone—the coach, the manager, maybe a more senior manager—needs to understand why deployment takes the time it does.
There might be good reasons for that delay.
Of course, there might not be.
When teams start to assess their cycle time and lead time, they can create forecasts that mean something useful.
We talked about making work smaller and still coherent. In addition, once the team measures its cycle time, it can decide how to make that time more consistent to have fewer outliers.
However, that is not quite enough for most organization‘s planning needs because you also need other data to create a better story about the team’s progress.
Please return for Part 4, where we’ll discuss how to create forecasts based on historical data.
Part 1: How Much Lean is in Today’s Agile?
Part 2: Adaptability Enhances How We Work
Part 3: Looking at Systems to Enhance Outcomes.
Part 4: Explain dates to anyone with forecasts based on your historical data
Part 5: A Little Lean Can Create a Whole Lot of Positive Change









