
As Pivotal Cloud Foundry R&D has grown, we’ve figured out a successful, non-traditional approach to Program Management. Our strategy has been to follow the principle of self similarity, ‘leveling up’ the principles and practices followed by our Extreme Programming(XP) development teams to the larger Programs they’re a part of. In this experience report we’ll discuss which team-level practices and principles have scaled up nicely along with some that have turned out to not apply as well as we originally hypothesized.
1. INTRODUCTION
I arrived at Pivotal 5 years ago, during a transitional point in our company’s history. At the time, Pivotal Cloud Foundry was beginning to apply product and engineering structures and practices the company had honed in its consulting practice over many years to our first long-term, sustaining software program. As our Program Management function has grown up since that point, we’ve found the most successful strategy to scaling has been to use the principle of self-similarity to establish program practices that are based on how our individual teams operate. This experience report will tell the story of what has worked, what hasn’t, and what we’re still experimenting with as we’ve scaled up XP from 10 teams in San Francisco to what’s now 60+ teams and 8 offices around the world.
2. Background
Pivotal has been employing agile software development methodologies for a long time. Our founder and CEO Rob Mee began Pivotal Labs as a small software consulting firm back in 1989, later going on to collaborate with some of the key figures in the XP community. Over time, Pivotal Labs developed an opinionated and disciplined approach to building software. Our clients, working alongside Pivots (that’s what we call ourselves), deliver real value to their customers through consulting engagements, learning our practices along the way and bringing them back to their own companies.
Here’s a quick description of what you might see if you walked the floor and observed a team at one of our offices:
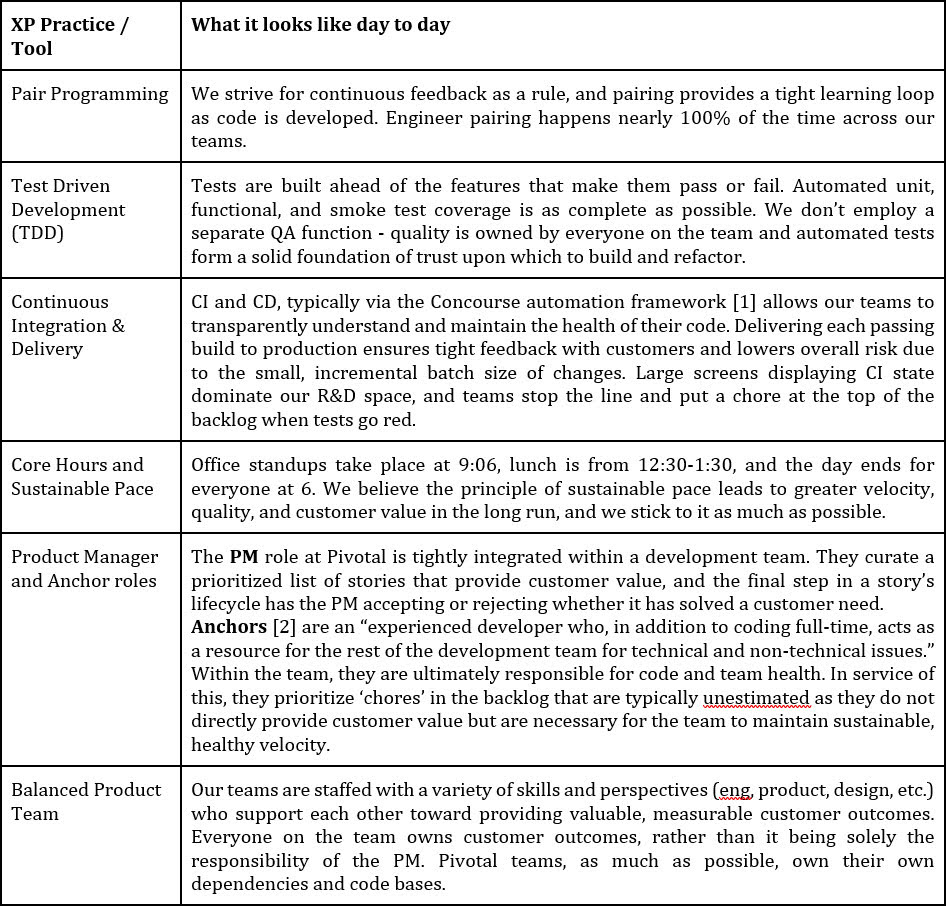
I’m a believer in the Lean Principles, and upon arrival many were clearly evident in the methods and values with which Pivotal teams approach their work. This disciplined approach also meant that, for me as a former Agile Coach, few, if any, of my old tools and tricks were applicable when it came to coaching individual teams. The teams were already ‘transformed’ and functioning optimally within their local contexts.
However, I did have to ask myself “Where is ‘Optimize the Whole’?” Mary and Tom Poppendieck [3] have a great line about this: “(t)he synergy between the parts of a system is the key to the overall success of the system.” Our system was moving beyond a single team, and we needed to account for the complexity that was now necessary to achieve ‘synergy’. With the Pivotal Cloud Foundry(PCF) project involving 10 teams by this point, focusing on Optimize the Whole was a dawning need. The messy realities of many teams working on the same code toward big, shared customer outcomes made single-team local optimization untenable. We had to figure out a new path forward, one that allowed us to remain aligned and focused on bringing customer value, but at the same time enabling coordination of that delivery across many teams.
A bit more history is in order: in 2009 Pivotal Labs was acquired by EMC. This eventually led to the creation of Pivotal in 2012, a company that combined VMware and EMC acquisitions Pivotal Labs, Spring, Greenplum, Gemfire, and a promising OSS Platform as a Service(PaaS) project, Cloud Foundry. A PaaS allows customers to develop, run, and manage applications without the complexity of building and maintaining the infrastructure typically associated with developing and launching an app. In the case of Pivotal Cloud Foundry, which is our commercial distribution of the OSS project, the majority of our customers download our software and install and manage it within their own data centers or cloud infrastructure services (IaaSs).
I came from a background in Software as a Service(SaaS), and this new world of large downloadable binaries, long feedback loops, and support lifecycle constraints for products out of our direct control was pretty foreign. In our software delivery system, there were (and still are) Open Source Software(OSS) teams building the Cloud Foundry(CF) PaaS that are composed of a mixture of Pivotal and CF Foundation employees from companies like IBM, SAP, and VMWare. In parallel, proprietary, Pivotal-only teams integrated those OSS components along with commercial-only features to produce a valuable distribution of Cloud Foundry. Our customer base, then and now, consists of large Fortune 500 companies who operate under tight regulatory, security, and customer requirements. Our teams needed to be able to navigate all this complexity without adding coordination overhead.
Again, many of the old coaching, program, and release management tricks that applied to SaaS needed to be reassessed or even thrown out in this new context. The consistent approach we chose to take was to build upon our strong foundation of team-level practices as we established the PCF Program. We followed the principle of self-similarity as we developed the program practices that would work well within our system. We took this approach for a few reasons:
- Building on existing practices was easy to understand for program participants who were already familiar with them on their teams and day-to-day work at Pivotal.
- A focus on the ‘care and feeding of feedback loops’ aligned well with successful Program Management patterns I’d experienced in previous enterprise software development contexts.
- Building on strong existing practices, rather than bringing in a new set of practices and procedures, helped us run the program as lean as possible and bias against introducing friction and overhead into the system.
3. Practices and Tools
This section describes program practices and tools we established, guided by self-similarity to what our teams were already experiencing, in order to help everyone work and deliver better, together. They’ll be presented in the order in which we began them, and for each I’ll describe:
- Problems we hypothesized would be solved through the introduction of the practice and / or tool.
- A description of the practice / and or tool as well as the team-level constructs we were ‘leveling up’ to the program.
- Results and Lessons Learned from implementing the program practice and/or tool. Was it successful? Do we continue to practice it? What has it evolved into?
3.1 PCF Program Standup
Problems we were trying to solve: Rather than conduct a weekly or biweekly Scrum of Scrums or program review, we hypothesized that a daily touchpoint would help the program remain in alignment and reduce friction to delivery flow. Prior to the standup, teams had relied on ad hoc communication for coordinating dependencies and solving blockers. There also had been a lack of a shared sense of mission and purpose toward a unified goal amongst the program participants, and the standup intended to reinforce a shared mental model of and sense of belonging to the larger team they were now a part of.
Description: One of the first new rituals we implemented in the PCF program was a standup attended by program management, the product managers from each product team, and engineering leadership. It later grew to include design, technical documentation, and go to market staff. This daily, 5-10 minute session was facilitated by technical program managers and immediately followed office and team standups during West Coast morning schedules, allowing participants to get all of their daily meetings out of the way prior to heading back to their teams. Attendees provided any of these three items if they had something to share on a given day:
- Helps: Does any team in the program need help from another team? This allowed teams to surface blockers and then self-organize around resolving them together rather than in 20+ response email chains.
- Interestings: Has any team in the program learned something new in the last 24 hours that would benefit other teams? This allowed our teams to broadcast new information in real time and for receiving teams to immediately follow up with questions and clarification.
- Events: What’s coming up in the near future that other participants in the program should be aware of and may want to attend or account for. Events were particularly helpful in projecting upcoming release milestones that we needed teams to prioritize some action around.
Results and Lessons Learned: The standup was incredibly useful for the first few years of the program. It supported the coordination of release activities, announcing and triaging cross-team bugs, handling dependencies, and resolving confusion in real time. However, at a certain point the total number of teams and locales increased (the tipping point for us was around the 40-team mark, across 7 offices) to where it became inefficient to gather everyone for a daily, synchronous touchpoint. The collaboration forum that standup once provided has since evolved into a few different things:
- Locale-based cross-team standups in individual offices.
- A ‘pub/sub’, asynchronous communication system where immediate blockers are made visible and triaged in purpose-built Slack channels, while more general team and product updates are sent out via weekly ‘drumbeat’ emails from individual product teams.
- The introduction of a more focused ‘ship room’ standup that takes place amongst directly involved teams and stakeholders during the last 3 weeks of each quarterly release cycle.
All in all, our learning has been that a real time, short standup is the most efficient way to collaborate across a program on a daily basis, with the bonus of being self-similar to what the individual teams are already used to. However, there is a certain size at which active collaboration begins to involve only a minority of program participants. Indicators that showed we needed to make a change were when the majority of involved teams are either providing feedback during retro that the session doesn’t provide the same value as it did in the past, or have simply voted with their feet. We then refactored, pushing the ritual closer to smaller clusters of teams aligned to a specific customer problem area. However, devolving to smaller group collaboration risked losing out on shared context across the program. We have mitigated this through asynchronous, opt-in communication. This has been a healthy evolution, in our experience.
3.2 Release Anchor Role and Program Management Team Structure
Problems we were trying to solve: For the first couple years of the program, minor and major releases of the PCF platform and application runtime tended to experience higher-than-comfortable levels of surprise and unpredictability. Late product changes or issues we discovered in integration would push our dates out, stakeholders and customers would lose confidence in our forecasts, and generally, the end of each cycle could turn into a slog for program participants. At the time, our release goals were defined by scope – whether we had completed all the features we intended to include – and while this approach delivered quite a bit of value to our customers, it all felt like it happened with too much drama and waste.
Not coincidentally, I was the only Technical Program Manager (TPM) on staff during those first two years and over that time I wore many different hats, such as PM for our Release Engineering team, facilitator at large across the org, and Release Manager for our platform and application runtime. This meant that no one was focusing 100% of their attention on any one of those areas, and the program and our releases were suffering as a result. It was at this point that we decided to expand the team and to better define the roles the TPM function played.
Description: We hired our first TPM not named Evan in January 2016, and since then have grown the team to include 9 amazing individuals who support a 500+ R&D organization. Since our inception as a team rather than a single individual, we have tried to organize TPM using the same patterns our product teams employ. This has led to practices such as:
- “Pair Program-Managementing” (as we call it) within the team where two or more TPMs collaborate in real time on a problem to solve, a document to write, a meeting to facilitate, etc. Unlike our engineering teams, we don’t pair 100% of the time due to current staffing levels and coverage needs. However, we do use it as a useful and fundamental tool in our problem-solving kit.
- Prioritizing cross-cutting work impacting R&D in a single backlog that the TPM team pulls from. This has had mixed results as we have learned to balance the needs and activities within the individual programs each of our TPMs are directly involved in against outcomes we are trying to impact across our entire organization. As our use of a backlog has evolved, we’ve ended up focusing it primarily on strategic organizational improvement initiatives that TPM can all share and contribute to, such as implementing an Alpha release program to enable faster product feedback or rolling out the infrastructure to support Objectives and Key Results(OKRs) across our product teams.
- As a team of TPMs, we participate in our own weekly iteration planning and retrospectives to keep in alignment and learning from each other. We attend a standup every day in which we seek out opportunities to help each other and pair within the team.
I’ll dive a bit more into the Release Anchor role, as it’s been one of the more successful experiments in ‘leveling up’ a practice within the TPM team and directly addressed the problems in our release cycle I described earlier. It rotates amongst TPMs – we’ve landed on a cadence where each person in the role spends 2 release cycles (6 months) in it. This allows a TPM to apply what they learned in a previous cycle to the next one, as well as onboard the next Release Anchor, who shadows and pairs in. Release Anchors are analogous to the anchor role within our engineering teams in that they facilitate code quality, sustainable pace, coordination amongst, and continuous improvement for the teams participating in the release. They accomplish those outcomes by performing activities such as:
- Maintaining visibility on the cross-cutting work targeted to a release which requires many teams to work in alignment toward a shared customer outcome. The Release Anchor helps our product team convey this work to impacted teams who will need to take some action, which is usually prioritizing a story high enough on their backlog to make the release. They ensure that the customer need and ‘why’ behind an ask is understood by impacted teams, as we would expect to take place between a single PM and their team.
- Interfacing with external-to-R&D go to market functions across Pivotal to make sure the customer needs they represent are being met effectively across the program.
- Over the course of a cycle, managing activities around individual milestones we’ve established to ensure healthy delivery. These milestones include shipping Alpha builds to our early adopter customer program for feedback as well as internal, cascading feature freeze targets. As we close in on shipping, they facilitate a ‘go / no go’ daily standup in the 3 weeks leading up to a release. This daily collaboration point between teams involved enables rapid resolution of blockers as they are discovered.
- Keeping a daily diary of events that take place over the course of the 3 month cycle. They then facilitate retrospectives after we’ve shipped, and take the lead on applying action items identified to improve the release system into the next cycle.
Results and Lessons Learned: Establishing a go-to individual focused on maintaining the health and flow during a release cycle has provided much-needed clarity to teams participating in the program. The fact that the role is analogous to an Anchor on an individual team helps set expectations around focus and responsibilities. We haven’t siloed a release manager role into a separate function from TPM, which helps bring fresh perspectives and learning within the team with each rotation. That pattern – that any TPM will eventually participate in a Release Anchor rotation – helped establish that generalization and continual learning are strong values for us, much as it is within our product teams, where engineers typically rotate to a new team every 9-12 months.
On the other hand, if the batch sizes and cycle times of our releases were much, much smaller there would be less need for the coordination, oversight, and communication that the Release Anchor provides. Our north star goal in the TPM team is always to ‘work or automate ourselves out of today’s job so we can focus on the next problem’. The improvement we facilitate in the ‘release value stream’ is always pointed in that direction, and as we progress through our next several cycles we’ll continue to work to reduce batch size and decrease the time it takes to understand and learn from the value our customers are receiving from the features shipped.
3.3 Master Pipeline for Cross-Team Continuous Integration
Problems we were trying to solve: Unlike a SaaS, PCF ships major, minor, and (many) patch releases of downloadable binaries of our product across several supported release lines. Given an asynchronous product delivery and customer installation pattern, it was difficult to conceive of a way to replicate the same feedback that teams following CI / CD practices enjoy when deploying to a hosted site immediately upon automated tests going green.
At our product line expanded to include many services that install directly on top of the PCF platform and application runtime, we ran into additional issues. Although we strive to maintain backwards-compatible contracts between products and components, as PCF has expanded we have a bit of a race against entropy to battle against. We needed to become more resilient to platform and individual product changes. As our customers’ installations have matured, upgrade scenarios have the potential to become combinatorial explosions of platform, runtime, and services versions.
Description: To meet this growing concern, we established a cross-product continuous integration team – Master Pipeline. They automate validation of cross-product compatibility and keep it visible to teams participating in the program. While this isn’t exactly Continuous Delivery, we have been able to make the ‘releasable’ state of our products visible to all teams participating in the program so they can take action when that integration breaks in some way. The team was established about a year and a half ago to apply the patterns our individual teams follow around CI and prioritization of automation tooling to ensure the delivery health of the entire PCF product suite. They are not an end-of-the-line QA team. Rather, their CI tooling watches for new releases posted to an internal distribution site. Once a new version of a product is noted, it’s picked up and installed automatically via the system. Integration and smoke tests that the product teams themselves include within their products are run to validate health.
All teams have access to several Master Pipeline dashboards that keep the state of the product integration visible. Here’s an example of the primary dashboard we watch, which displays health status for all products and Infrastructures as a Service(IaaSs) PCF installs against. Clean installation and upgrade scenarios are run across all supported release lines:
 Figure 1. Master Pipeline Dashboard
Figure 1. Master Pipeline Dashboard
Results and Lessons Learned: Master Pipeline enables teams participating in the program to decrease the cycle time to understand whether they are shippable along with the rest of the product suite they are a part of. It has reduced late surprises as we make progress toward minor and major releases as a result of smaller batch size of changes integrating into the whole suite of products. In the past, when a multi-product-impacting change was introduced in our platform we needed to coordinate the testing of that change via each individual team’s backlog, which was disruptive to those teams and required a ton of coordination overhead. Now, with Master Pipeline, we can more efficiently validate whether a change will be breaking to some or all of the product teams.
However, our ‘Program CI’ is still working toward realizing the potential value we hypothesized it would provide when the effort kicked off. There is more manual intervention needed by the team to keep test pipelines up and running than we’d like, and in order to scale in the future we realize that the balance of interaction with the system needs to shift more to the product teams themselves. We are now focused on building Master Pipeline as a ‘platform’ that every program team has at their disposal and is incented to interact with, rather than as a service that is maintained and curated by a single team. The team’s roadmap also includes supporting additional test scenarios (chaos, longevity, stress, etc.) beyond what is currently available.
All told, introducing CI at the program level has been a valuable undertaking. It built confidence throughout our release cycles versus only toward the end, as everything came together. Using the same construct of visible CI information radiators that teams already were paying attention to in their local contexts has helped participants feel like it’s a natural evolution rather than a foreign concept.
4. In Conclusion…
In this paper, I’ve discussed a small set of practices and tools our program has found to be successful. These, and several others we utilize, each originated from inspecting what was working for our individual teams in our environment and then figuring out how they could be applied to the next ‘layer in the organizational onion’. Here’s a quick rundown, revisiting the earlier team-level examples I mentioned and matching them up with the system at scale:
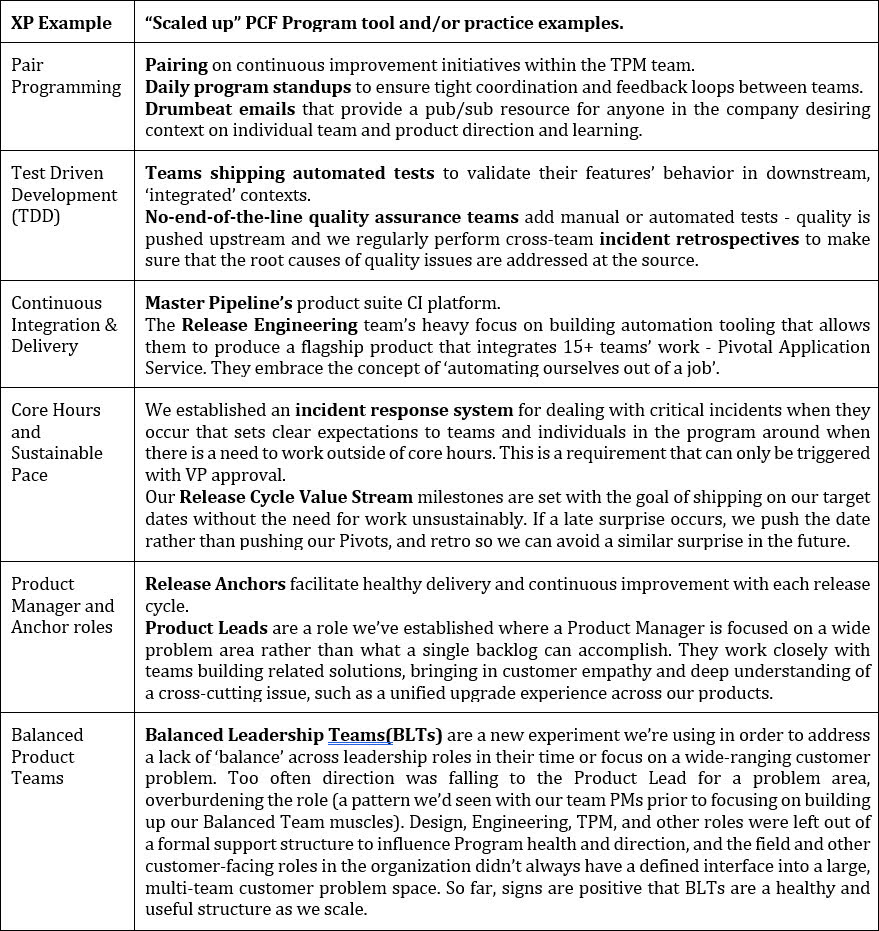
I encourage you to ask the question when establishing or refactoring a multi-team program – how can you take patterns that are already successful and familiar to the teams involved and level them up? Keep in mind that this approach hasn’t been a panacea. We’ve grown beyond several practices and are continuously refactoring as we scale. There have been some experiments in self-similarity, such as aligning around a single detailed backlog to organize work across all teams, that have not worked out. Our org collaborates at all levels to improve the systems with which we deliver and recognize value to our customers. It’s no one person’s or team’s responsibility to ensure the system is adapting and changing for the better – it’s everybody’s. This kaizen mindset is at the core of how we’ve been able to scale as successfully as we have, and allowed our core values of Do What Works, Do the Right Thing, and Be Kind to come along for the ride.
Our current focus areas of improvement are around moving agency and decision-making authority closer to the individuals who have the most context and information – the balanced product teams themselves. We are building the muscles to better convey org and company-wide intent. We are attempting to foster even greater self-organization of teams to arrive at and utilize the right strategies to actualize and measure customer outcomes. The TPM team’s part of this effort is to support product teams’ learning around both the mechanics of and the ‘why’s’ behind the tools we’re introducing to our R&D org in this initiative, such as team charters and OKRs. Next time we update this experience report we’ll let you know how that’s gone!
5. Acknowledgements
I’d like to send a few shout outs to folks who have helped me along the way: Product, Engineering, Docs, Design, and other teams within Pivotal R&D and many, many others throughout Pivotal who have been great partners and supporters of TPM, and who give me so much to think about when it comes to doing the right thing – the ‘Pivotal Way’. Keith Nottonson and Derek Hawkes, who taught me what the ‘Player Coach’ model is when transforming the way teams adopt an agile, lean mindset and practice from the trenches. Elisabeth Hendrickson, who besides being pretty amazing when it comes to quality, teams, facilitation, and dealing with complexity, was also the main reason I got a chance for a job at Pivotal in the first place. The amazing Pivotal Cloud R&D TPM team, which challenges and teaches me new things every day and are so much better at the TPM gig than I ever was. Tom Lee and John Cutler, who reviewed and gave some fantastic feedback on this report. My awesome wife Karen who copy edited this report. Keith Buehlman and the rest of the folks at the Agile Alliance who have provided this platform for me to spout off from and guided me toward crafting what I hope could be a useful resource for others looking to grow an XP program.
REFERENCES
[2] Holzer, Morgan. “The Pivotal Glossary” https://builttoadapt.io/the-pivotal-glossary-93b8be9de916
[3] Poppendiek, Tom and Mary. http://www.poppendieck.com/


